
Como montar um pipeline de dados com Web Scraping, Automação e Visualização em Power BI (sem escrever código)
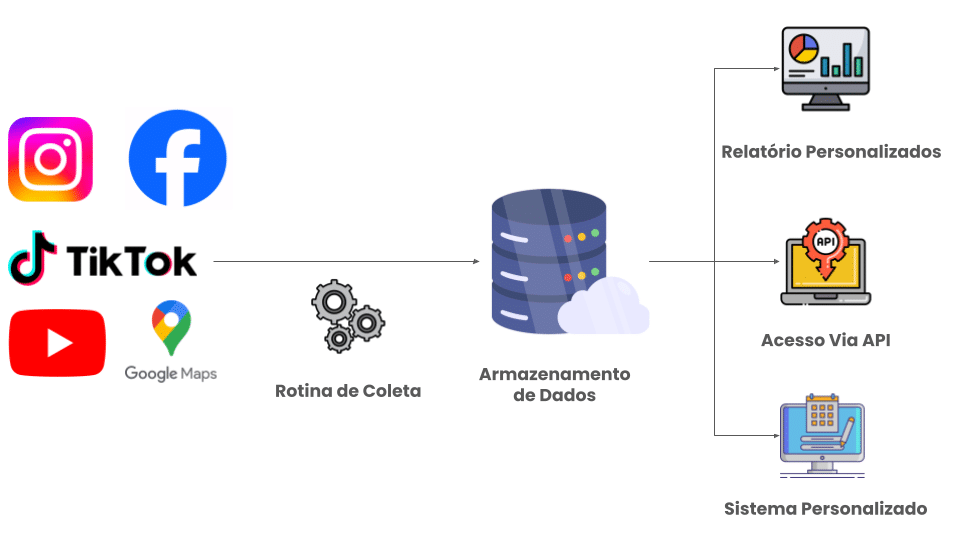
Vivemos na era dos dados — mas o maior desafio não é ter acesso a eles, e sim coletar, organizar e transformar essas informações em insights visuais e acionáveis.
Se você é um analista, desenvolvedor, profissional de marketing ou empreendedor que precisa lidar com dados de redes sociais, plataformas públicas ou sites diversos, provavelmente já se fez essa pergunta:
“Como posso automatizar tudo isso e transformar dados públicos da internet em gráficos prontos para análise?”
Neste artigo, apresento um processo completo que soluciona esse desafio. A proposta é simples: criar um pipeline de dados do zero, capaz de coletar, transformar, armazenar e visualizar dados sem a necessidade de programação tradicional.
📌 O que você vai aprender neste artigo?
- Como montar um pipeline de dados completo com ferramentas low-code
- Quais ferramentas usar: Apify, n8n, Supabase e Power BI
- Como funciona a integração entre cada etapa
- Aplicações práticas para empresas, analistas e freelancers
- Como evoluir o projeto para soluções comerciais
🧱 A Stack Usada (Low-Code e Open Source)
A ideia aqui é usar ferramentas acessíveis, flexíveis e de baixo custo. Veja a arquitetura completa:
- 📦 Apify: Coleta os dados de qualquer site público via Web Scraping
- 🔁 n8n: Automatiza o fluxo dos dados (ETL: extração, transformação e carga)
- 🗃️ Supabase: Banco de dados relacional na nuvem, baseado em PostgreSQL
- 📊 Power BI: Plataforma de visualização e análise interativa
🕸️ Etapa 1 – Coleta de Dados com Apify
- O primeiro passo é extrair os dados. O Apify é uma plataforma de scraping que oferece actors prontos para capturar dados de plataformas como:
- Instagram (seguidores, posts, comentários)
- TikTok (vídeos, perfis, sons, hashtags)
- YouTube (dados de vídeos e canais)
- Google Maps (estabelecimentos, reviews, localização)
Benefícios:
- Interface simples
- Agendamento de execuções
- Scrapers prontos para uso
- Exportação via API, CSV ou JSON
A coleta pode ser feita com base em palavras-chave, perfis específicos ou categorias de busca — tudo configurável.
🔄 Etapa 2 – Automação com n8n
Depois de coletar os dados, é preciso automatizar a forma como eles são processados e enviados para o banco. O n8n é a ponte entre o Apify e o Supabase.
O que o n8n faz:
- Recebe os dados do Apify via Webhook
- Filtra, limpa e transforma os dados
- Adiciona lógica condicional (ex: evitar duplicações)
- Envia para o banco Supabase via API REST
🧩 Etapa 3 – Armazenamento com Supabase
Com os dados tratados, é hora de armazenar de forma organizada. O Supabase funciona como um backend completo:
- Baseado em PostgreSQL
- Painel web para gerenciar dados
- API REST gerada automaticamente
- Regras de autenticação e permissões
- Grátis para projetos pequenos
Ideal para quem quer a estrutura de um banco relacional com a simplicidade de um Firebase.
📈 Etapa 4 – Visualização com Power BI
A etapa final é visualizar e analisar. O Power BI se conecta facilmente ao Supabase via conector PostgreSQL.
Com os dados carregados, você pode:
- Criar dashboards personalizados
- Filtrar por período, plataforma, perfil, tipo de conteúdo
- Comparar performance entre diferentes fontes
- Automatizar atualizações via agendamento
💡 Aplicações Práticas
Essa estrutura pode ser adaptada para dezenas de cenários:
| Setor | Aplicação |
| Marketing | Monitorar performance de influenciadores, posts e campanhas |
| Vendas | Coletar leads de empresas no Google Maps |
| BI | Criar relatórios automatizados de concorrência |
| Growth | Rastrear hashtags, tendências e menções |
| Pesquisa | Coletar dados de opinião pública em comentários ou reviews |
🎯 Por que essa solução é poderosa?
- Totalmente automatizável: do scraping ao gráfico
- Flexível: coleta dados de qualquer site com HTML acessível
- Econômica: uso gratuito ou baixo custo para todos os componentes
- Escalável: integra com outras APIs, plataformas ou dashboards
Você pode começar com um projeto simples e expandir para soluções robustas.
🔧 Recursos complementares (em breve no blog):
- Como instalar o n8n local com ngrok para testes
- Como usar webhook.site e Postman para simular dados
- Como publicar e agendar actors no Apify
- Como automatizar o pipeline com Make
- Como proteger e escalar seu banco Supabase
✅ Conclusão
Criar um pipeline de dados nunca foi tão acessível.
Essa solução permite que analistas e equipes criem uma plataforma de dados personalizada, conectando informações de redes sociais, mapas, vídeos, comentários e qualquer site acessível — com a entrega final sendo dashboards profissionais e atualizados em tempo real.
Se você trabalha com dados e quer montar sua própria estrutura de coleta, automação e visualização, essa arquitetura pode ser o ponto de partida ideal.
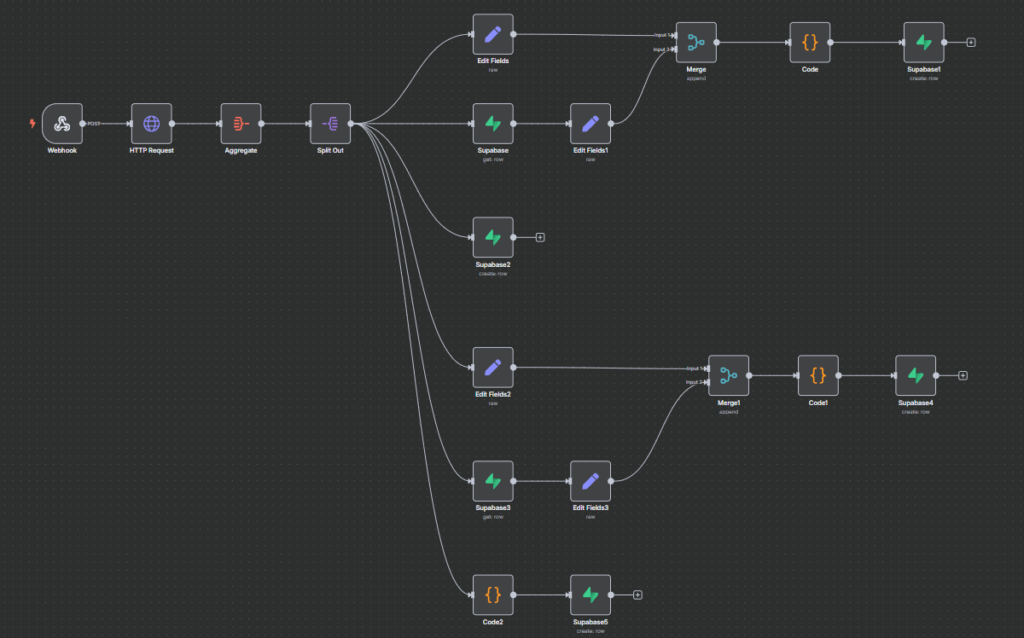
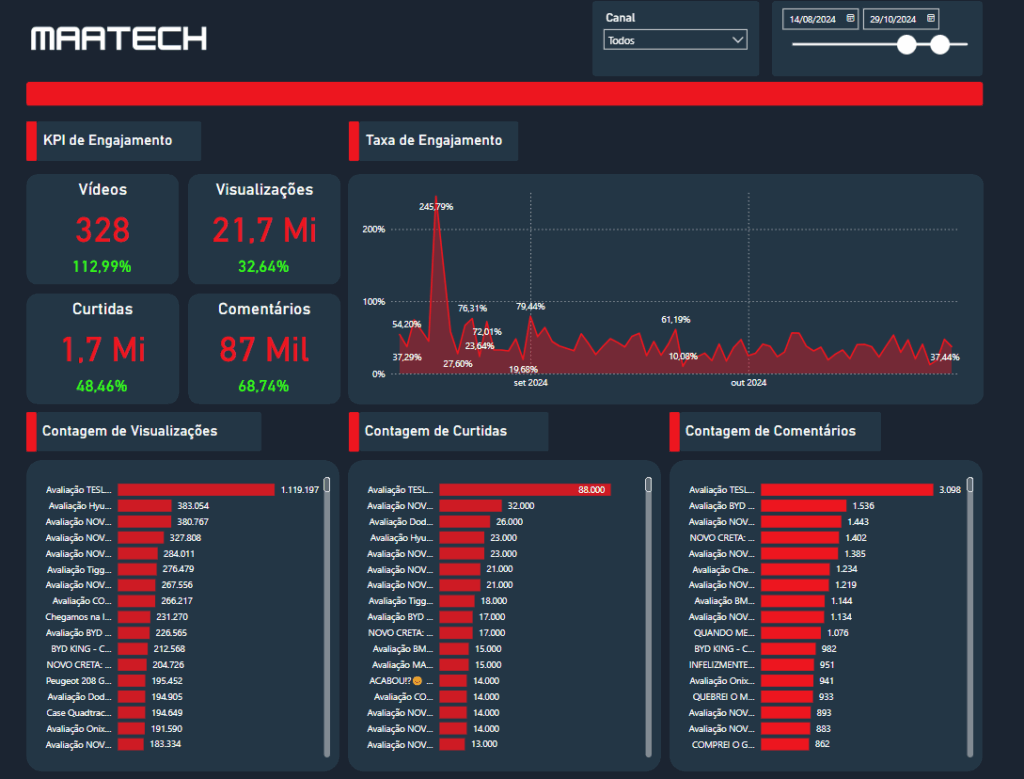
💬 Quer aprender como montar esse projeto passo a passo?
Nos próximos artigos do blog, vamos quebrar essa jornada em três partes:
- Apify + n8n + Supabase
- Supabase + Power BI
- Dicas técnicas complementares (ngrok, Postman, Make, webhook.site)
<script>
// Inputs: todos os itens | e identificados
const allItems = $input.all().flatMap(item => item.json.id ? [{
id: item.json.id,
chanelId: item.json.chanelId || "",
title: item.json.title || "",
url: item.json.url || "",
thumbnailUrl: item.json.thumbnailUrl || "",
duration: item.json.duration || "",
data: item.json.data || "",
type: item.json.type || ""
}] : []);
const identifiedItems = $input.all().flatMap(item => item.json.videoIdSearch || []);
// Filtrar apenas os não identificados
const nonIdentified = allItems.filter(item =>
!identifiedItems.includes(item.id)
);
// Remover duplicados (manter apenas 1 item por ID)
const uniqueItems = [];
const seenIds = new Set();
nonIdentified.forEach(item => {
if (!seenIds.has(item.id)) {
seenIds.add(item.id);
uniqueItems.push(item);
}
});
// Retornar os resultados incluindo todas as variáveis do objeto
return uniqueItems;
</script>